危险行为识别
调研接口描述(百度)
针对5s内的监控视频片段,识别行为类别,目前支持7类行为:单人-情绪性指人、单人-摔倒、单人-激烈抱怨、单人-砸东西、单人-正常、双人-危险(包含出拳/拉扯/推搡/激烈搂抱/砸按/踢踹等)、双人-正常。
注:不支持红外摄像头、支持普通照片与监控、当视频中人物超过2人时(比如有围观或者劝架)可能出现误识别(比如输出也是双人-危险)
测试结果
| 类别 | 正确率 | 结果(括号中为错误预测结果) |
|---|---|---|
| 双人危险 | 6/6 | 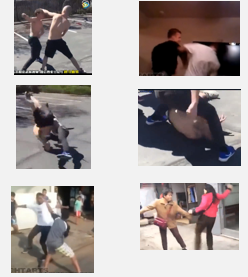 |
| 双人正常 | 1/6 |  |
| 单人摔倒 | 2/6 |  |
| 单人-砸东西 | 1/4 |  |
| 单人-激烈抱怨 | 0/1 |  |
| 单人-情绪性指人 | 0/2 |  |
| 单人-正常 | 1/2 |  |
测试结论
-
因为对暴力容错率较低,推测其设定为高召回率。从而导致双人有正常肢体接触(比如握手、拥抱、跳舞)就会判定为危险。
-
大部分场景都超过2个人,因此使用受限。
-
单人场景不准确,且时常检测出两个人。
-
处理时间较长,2 ~ 4 视频片段要30s ~ 100s,甚至更长,不适合实时使用。
能够使用的场景为:明显打架斗殴场景检测
大致原理(以TSN为例)
Temporal segment network
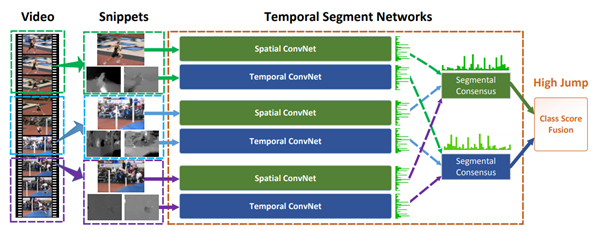
将输入视频分为K个片段、接着从每个片段随机选择一帧丢入空间结构(Spatial ConvNet)、以及选择一段片段(Snippets)丢入时间结构(Temporal ConvNet)、不同片段的类别得分采用段共识函数(The segmental consensus function)进行融合来产生段共识(segmental consensus),这是一个视频级的预测。然后对所有模式的预测融合产生最终的预测结果。