本质:一种顾全大局的行为
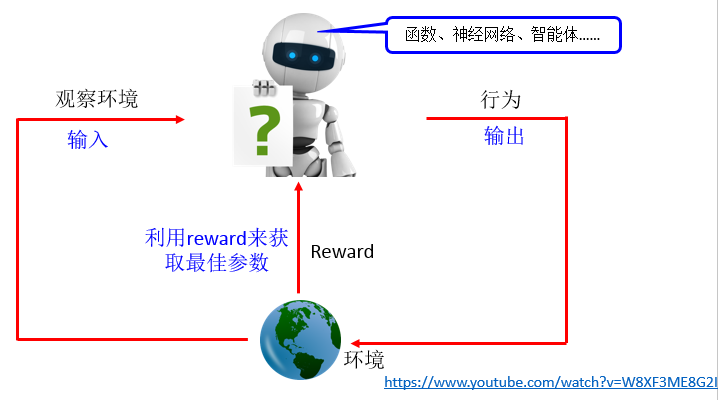
强化学习:machine 会对场景做出反应,并在整局(Trajectory)结束时候获得reward,在下次时以增加reward为标准行动。
监督学习:有个teacher告诉每次应当做出哪种反应,然后看看反应是否接近。
通常先监督学习、后强化学习。AlphaGO 便是如此训练的。
大厂应用:
- alphago
- 腾讯AI LAB 出的觉悟机器人
问题
- reward delay : 牺牲短期,获取长期利益
- action 会影响后续输入。
强化学习:machine 会对场景做出反应,并在整局(Trajectory)结束时候获得reward,在下次时以增加reward为标准行动。
监督学习:有个teacher告诉每次应当做出哪种反应,然后看看反应是否接近。
通常先监督学习、后强化学习。AlphaGO 便是如此训练的。